It’s been a few months so I wanted to say hey to the 7 of you who follow this blog and share a few updates about what I’ve been up to.
Quick recap
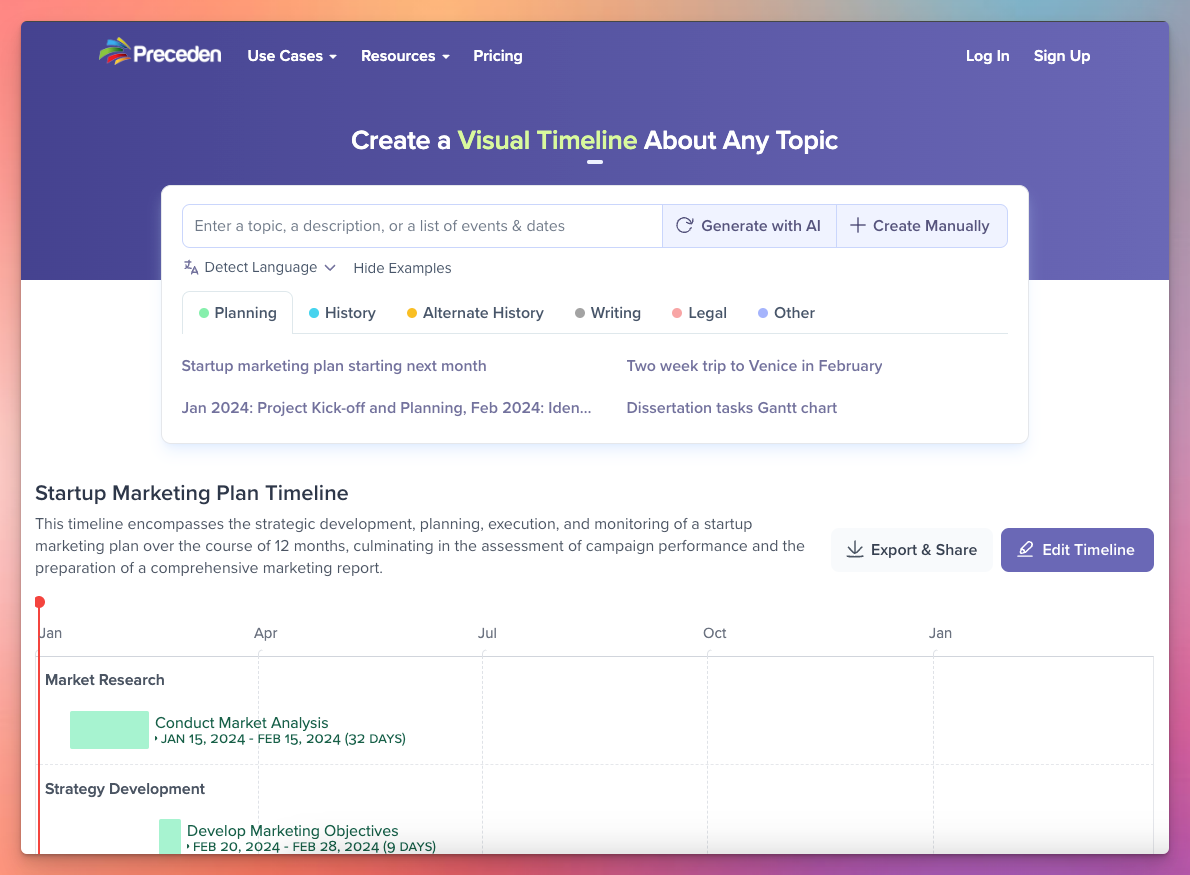
At the start of 2023 I quit consulting to go full time on Preceden, my SaaS timeline maker, after growing it on the side for about 13 years. Around the same time I started working on LearnGPT (which would eventually become Emergent Mind), and wound up spending about 70% of 2023 working on Preceden building out various AI capabilities like its visual timeline generator and 30% working on LearnGPT/Emergent Mind. In November I pivoted Emergent Mind from an AI news aggregator to an AI research aggregator, and I’ve been working on it full time since then.
Preceden
I’ve barely worked on Preceden since November. I answer about a dozen support emails each week and fix the occasional bug, but haven’t worked on any major product updates in a while. A good chunk of those support emails are refund requests, which I actually think is a good sign, because the lack of bug reports and feature requests reflect that the product is in pretty good shape.
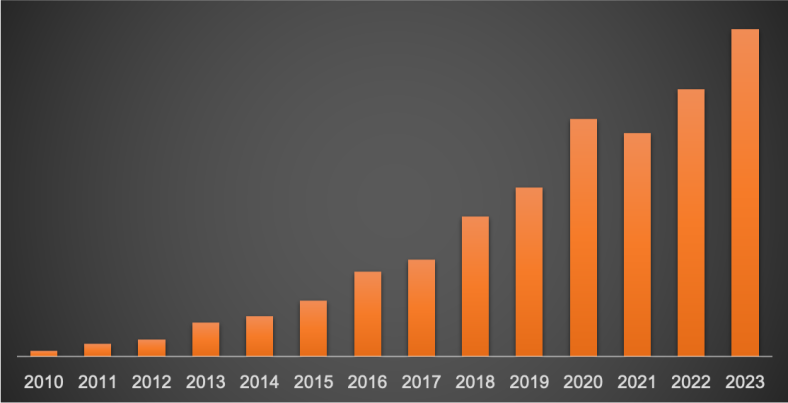
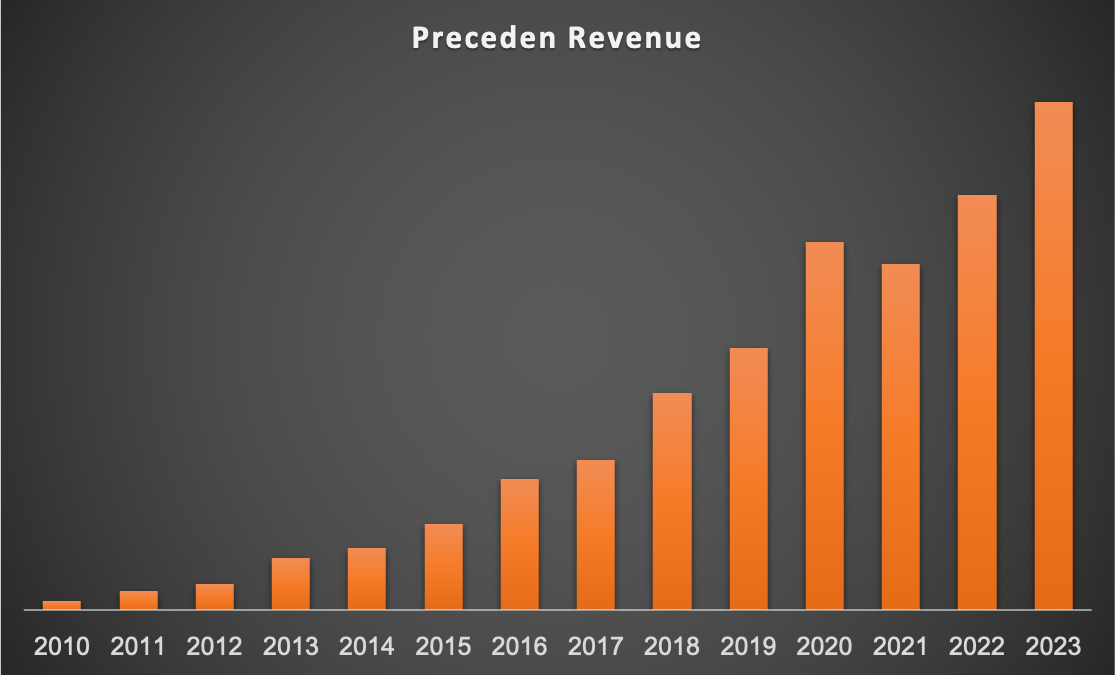
Preceden revenue is up about 5% year to date, the lowest it’s ever been. It’s tempting to see that and conclude that it’s because I haven’t worked on it in 5 months, but the reality is that churn finally caught up to new MRR growth, and it’s largely because of a subtle mistake I made in the fall.
Preceden has always struggled to rank well for key search terms like “timeline maker”, despite it having pretty good SEO positioning. I realized around October that the reason for this might be because over its lifetime lots of users have created near-identical public timelines on historical topics, like hundreds of timelines on the Russian Revolution. Maybe Google was penalizing the site for this duplicate content. To remedy this, I used the AI timeline generator I built to generate around 200 timelines on common historical topics, and then 301 redirected about 20k public user-generated timelines to the AI-generated ones in an effort to reduce the amount of content on Google that it was possibly interpreting as spammy.
Good thought, but one problem: I accidentally no-index all of those AI-generated timelines, and because I was heads down on Emergent Mind and not paying close enough attention to Preceden’s metrics, I didn’t realize it for about 4 months. Those 20k public timelines drove a lot of traffic and sign ups, and when I redirected them all to no-indexed pages, I lost all that traffic, and a good portion of Preceden’s new MRR disappeared as well. I got the AI-generated timelines re-indexed, but traffic hasn’t fully recovered, which is why revenue is up 5% and not higher like it’s been in the past.
The good news though is that despite this mistake, Preceden continues to bring in income equivalent to a decently-paid developer’s salary, and it’s entirely passive, allowing me to pursue other things.
I’m taking advantage of that and chilling on the beach reading all day. Except not at all.
Emergent Mind
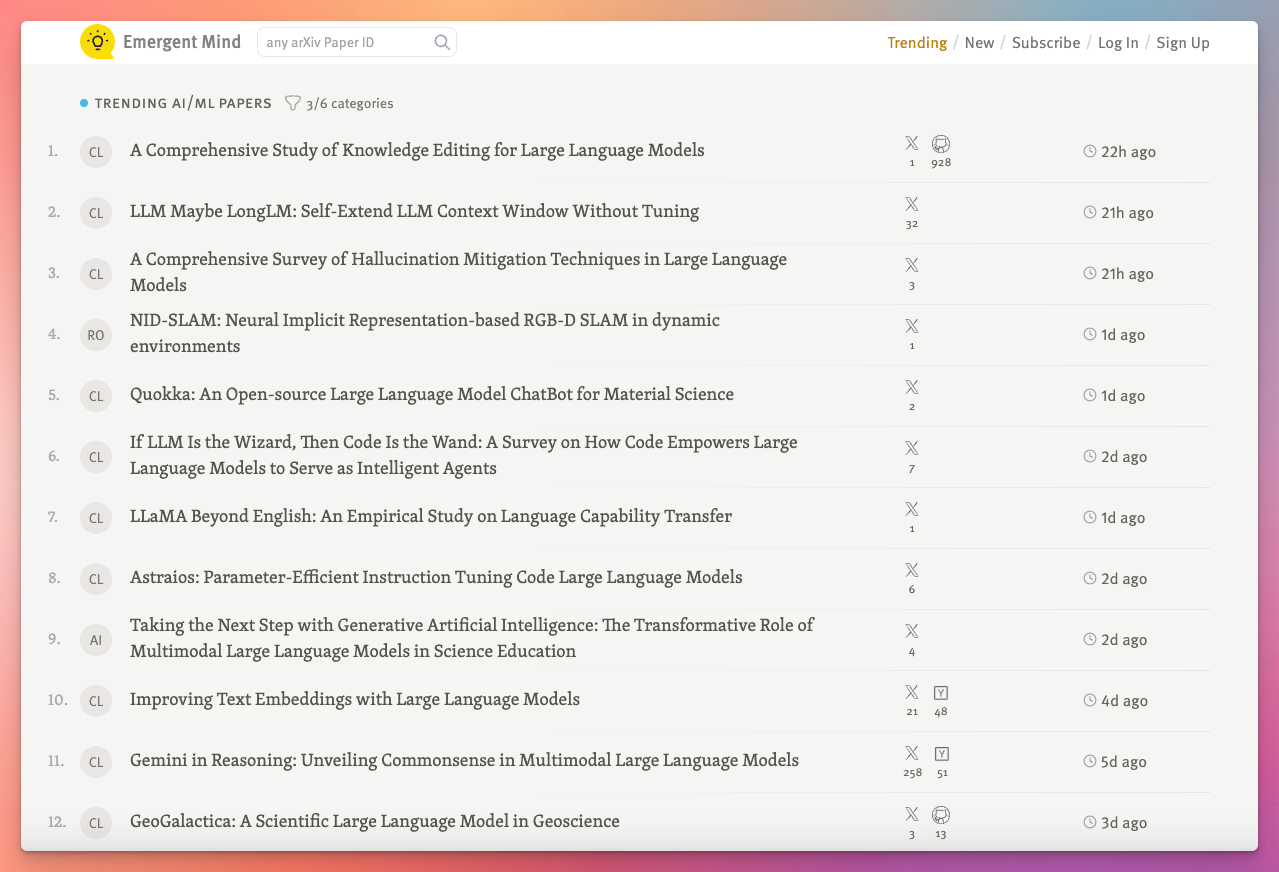
Emergent Mind helps people discover and learn about new AI/ML research. It gets 10k-15k visitors per month currently and people seem to get a lot of value out of it.
And last week I rolled out some very early paid plans and it now has non-zero revenue coming in:
It’s not much, but it’s a start.
The thing is though, I’m not optimizing for revenue right now.
I think of Emergent Mind as a product lab operating at the intersection of LLMs, research, and education. The way I see it, we’re at a point right now similar to the mid-90s when internet usage exploded with the advent of AOL. Similar to how many companies from that time period focused on building out better infrastructure to enable broader and faster internet usage, there are lots of companies right now focused on building bigger, more powerful LLMs. And similar to 1995, I think we’re going to see a ton of innovation in the coming years in the type of products and businesses being built with this new technology. That’s what I want to focus on.
I want to build tools in the research space at the frontiers of what’s possible with generative AI. I think we’ve seen like 2% of what’s going to be built with these technologies, and I want to spend most of my time exploring that other 98%. These will range from quick features that take several hours to launch, to some in the future that will take months to build. Some of these will be silly and most won’t go anywhere, but I think there’s a huge opportunity right now to tinker with an entrepreneurial mindset and create new types of innovative and hopefully useful products.
Like, what if you put an agent in charge of your Twitter account and set it up to automatically optimize itself based on engagement? What if you built a deeply integrated chatbot into your site that tried to persuade visitors to sign up for your newsletter based on their usage of the site? If you have access to the latest scientific research, could you use LLMs to identify gaps in our knowledge? Could you use LLMs to fill in those gaps? Could you build an AI-enabled educational tool that helps a software developer gain fluency in the type of advanced math you might find in a diffusion paper?
I don’t have the expertise to be confident about what’s going to work and what’s not (does anyone?), so I’m going to just experiment and learn and iterate and see where it goes.
With Preceden’s passive income, I can pursue this for a while, not forever. I do have a small team of amazing contractors helping out (Milan on design and Omar on AI engineering); it will be important to monetize Emergent Mind so I can support this team and possibly add more folks in the future. Ideally, Emergent Mind will make enough income at some point soon-ish where I can continue doing this long term without relying on Preceden’s income to support it.
Honestly there’s nothing else I’d rather be doing right now. For me, building a software business has always been about freeing up my time so I can spend more time learning and building. It took a while, but I’m kind of at that point right now where I can do that all day without being laser-focused on revenue growth.
I have no idea how this approach will play out, but I’m excited to see what happens.
Thanks for following along ❤️.